
这里有两个需要小心的点。
import java.util
import scala.collection.JavaConverters._
/**
* Java集合转换为Scala集合 使用JavaConverters的隐式方法,由父特质DecorateAsJava定义
*
* @author 梦境迷离
* @since 2019-09-25
* @version v1.0
*/
object JavaCollectionTest extends App {
val javaMap = new util.LinkedHashMap[String, String]
javaMap.put("1", "1")
//本质是通过适配器使用迭代器遍历
val scalaMap = javaMap.asScala.toMap //return Map(1 -> 1)
//这里toSeq里面实际就是toStream,延迟求值可能会影响实时性业务
val scalaStream = javaMap.values().asScala.toSeq //return Stream(1, ?)
println(scalaMap)
println(scalaStream)
}
任何迭代器需求注意的地方,调用asScala.toSeq/toMap都需要注意。特别是在并发情况下,若有线程在更新集合,此时调用asScala.toSeq/toMap的线程相当于在调用迭代器。 进而很可能发生ConcurrentModificationException异常。并且这个问题被隐藏的挺深,一不小心就不注意。若是直接使用iterator可能大家一眼就能想到是快速失败原理造成。 当然ConcurrentModificationException不只是出现在多线程环境下,单线程同样有这个问题。只不过一般使用LinkedHashMap实现LRU缓冲时,都是因为并发才做缓存使用(LinkedHashMap的构造函数accessOrder=true)。 因为这个问题最终还是迭代器的锅,所以在put时使用get(根据计算的hash获取而不是使用迭代器遍历)方法不会有这个问题,顶多就是get没找到,然后多存一份。这种情况就需要锁或其他同步处理LRU了。
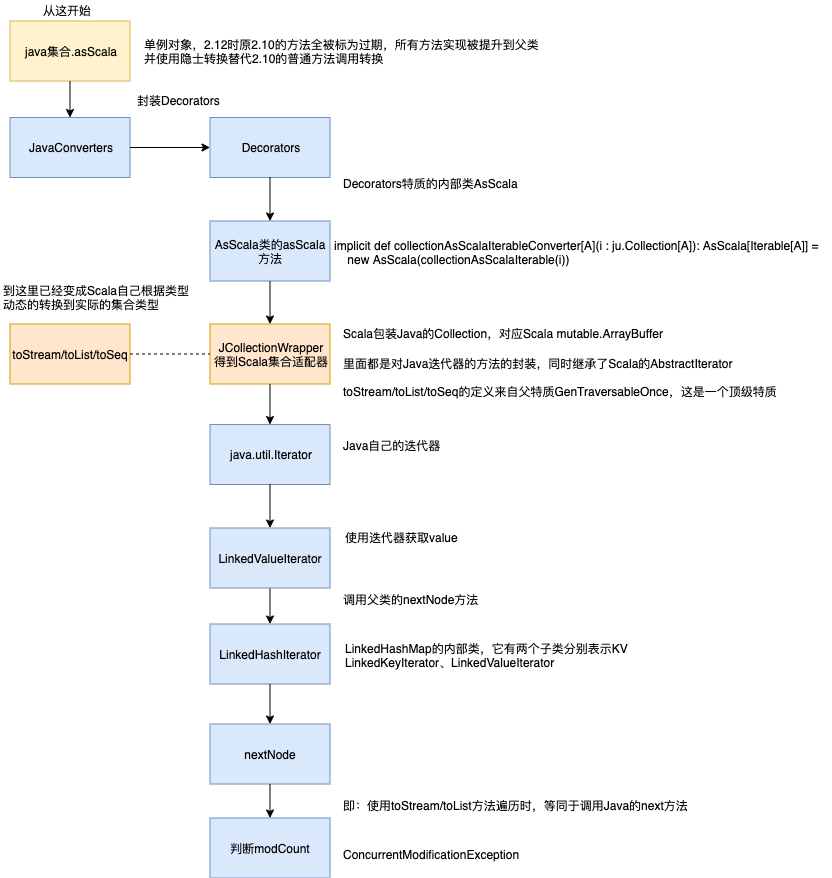
下面这张图简单描述了asScala的调用流程:
文档信息
- 本文作者:梦境迷离
- 本文链接:https://blog.dreamylost.cn/scala/Scala-Java%E9%9B%86%E5%90%88%E8%BD%ACScala%E9%9B%86%E5%90%88%E6%B5%81%E7%A8%8B.html
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)